Philosophers, theologians, and scientists have debated the concept of free will for centuries. The very likable concept of free will is at odds with the very nature of our observations — things tend to have causes. And so the question remains, how much decision-making freedom do we really have? And what’s this conscious “we” concept, while we’re at it?
In the 1800s, a rather well known mathematician made a bold statement with some long-ranging consequences. He said that if we knew the position and momentum of every particle in the universe, then we could calculate forward in time and predict the future. This built on the foundations of the physical laws that Isaac Newton observed and was the start of what became known as determinism. Since the brain is subject to physical laws (in essence, its functionality is a complex set of chemical reactions), this leaves no room for free will, which pretty much everyone believes they have.
“We may regard the present state of the universe as the effect of its past and the cause of its future. An intellect which at a certain moment would know all forces that set nature in motion, and all positions of all items of which nature is composed, if this intellect were also vast enough to submit these data to analysis, it would embrace in a single formula the movements of the greatest bodies of the universe and those of the tiniest atom; for such an intellect nothing would be uncertain and the future just like the past would be present before its eyes.”
—Pierre Simon Laplace, A Philosophical Essay on Probabilities
As modern neuroscience has developed, our understanding of the brain and of the mind has progressed. But as with all good research, every good answer leads us to more questions. Michael Gazzaniga is a neuroscientist and a professor at one of my alma maters. In Who’s In Charge he takes you on a journey through the concepts of emergence and consciousness, the distributed nature of the brain, the role of the Interpreter, and ultimately how these might change what we think about free will.
The conscious mind has considerably less control over the human body than it would like to believe. This is the underlying theme of the book. Gazzaniga’s personal career with split-brain patients (a treatment for severe epilepsy), and his review of modern neuroscience are convincing to that effect. While it is nice to think that “we” call the shots, it becomes clear that “we” aren’t always in charge and who this “we” is has some interesting properties.
“The brain has millions of local processors making important decisions. It is a highly specialized system with critical networks distributed throughout the 1,300 grams of tissue. There is no one boss in the brain. You are certainly not the boss of the brain. Have you ever succeeded in telling your brain to shut up already and go to sleep?”
What our conscious self thinks is largely the result of a process that takes place in the left hemisphere of our brain. Gazzaniga calls it “the interpreter.” This process’s job is to make sense of things, to paint a consistent story from the sensory information that enters the brain. Faced with explaining things that it has no good data for, the interpreter makes things up, a process known as confabulation. There is a story of a young woman undergoing brain surgery (for which you are often awake). When a certain part of her brain was stimulated, she laughed. When asked why she laughed, she remarked, “You guys are just so funny standing there.” This is confabulation.
“What was interesting was that the left hemisphere did not say, “I don’t know,” which truly was the correct answer. It made up a post hoc answer that fit the situation. It confabulated, taking cues from what it knew and putting them together in an answer that made sense.”
But the brain is even stranger than that. If you touch your finger to your nose, the sensory signals from the finger and from the nose take measurably different times to reach the brain. Different enough that the brain receives the signal from the nose well before it receives the signal from your finger. It is the interpreter that alters the times and tells you that the two events happened simultaneously.
This is where neuroscience’s contribution to the sensation of free will comes into play. Gazzaniga says, “What is going on is the match between ever-present multiple mental states and the impinging contextual forces within which it functions. Our interpreter then claims we freely made a choice.” This is supported by Benjamin Libet’s experiments which demonstrated that the brain is “aware” of events well before the conscious mind knows about them. Libet even goes so far as to declare that conscousness is “out of the loop” in human decision making. This is still hotly debated, but fascinating.
Gazzaniga argues that consciousness is an emergent property of the brain. Emergence is, in essence, a property of a complex system that is not predictable from the properties of the parts alone. It is a sort of cooperative phenomenon of complex systems. Or, as Gazzaniga more cleverly puts it, “You’d never predict the tango if you only studied neurons.” Emergence is a part of what’s known as complexity theory, which has increased in popularity in the last decade or so. But at this point, designating something as an emergent property is still really just a way to say you don’t know why something happens. And despite all the advances that have been made in neuroscience, we still fundamentally don’t understand consciousness.
Gazzaniga makes the case that the development of society likely had much to do with the development of our more advanced cognitive abilities. That is, as animals developed more social behavior, that increased cognitive skills were necessary, and that this was probably the driving force in the evolution of the neocortex.
“Oxford University anthropologist Robin Dunbar has provided support for some type of social component driving the evolutionary expansion of the brain. He has found that each primate species tends to have a typical social group size; that brain size correlates with social group size in primates and apes; that the bigger the neocortex, the larger the social group; and that the great apes require a bigger neocortex per given group size than do the other primates.”
There is some physiological evidence to support the relationship between society and neocortical function in the case of mirror neurons. First discovered in macaque monkeys, when a monkey grabbed a grape, the same neuron fired in both the grape-grabbing monkey and one who watched him grab the grape. Humans have mirror neurons too, though in much greater numbers. They serve to create a sympathetic simulation of an event which drives emotional responses. That is, the way we understand the emotional states of others is by simulating their mental states. So when Bill Clinton told Bob Rafsky that he felt his pain, perhaps he really did.
This is not Gazzaniga’s first book and it shows. The work is well planned and executed. He uses clear language to describe some of the wonderful discoveries of modern neuroscience, and makes them available for laymen to learn and enjoy. He discusses his own fascinating research, for which he is well known in his field, and also discusses other hot topics in neuroscience and their implications on modern society and also on the free will debate. He ends the book discussing how modern neuroscience can and should be used in regards to the legal system, which caught me somewhat by surprise. It is a fine chapter, but it doesn’t read like the rest of the book, feeling like a separate work that was added in as an afterthought.
I enjoyed Who’s In Charge? immensely. It is an excellent read and will undoubtedly challenge some of your thoughts and enlighten you about how we think about the mind and the brain today.


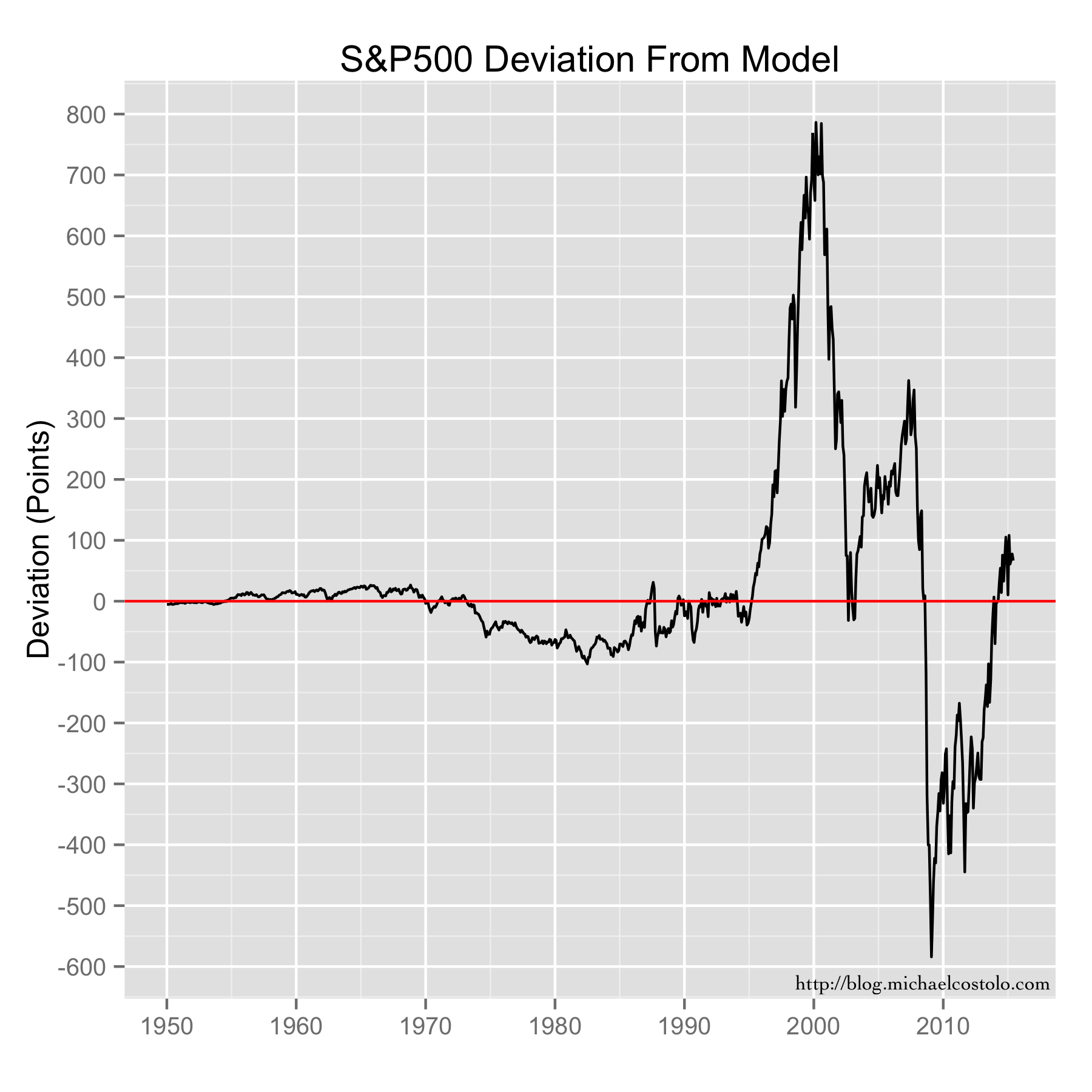
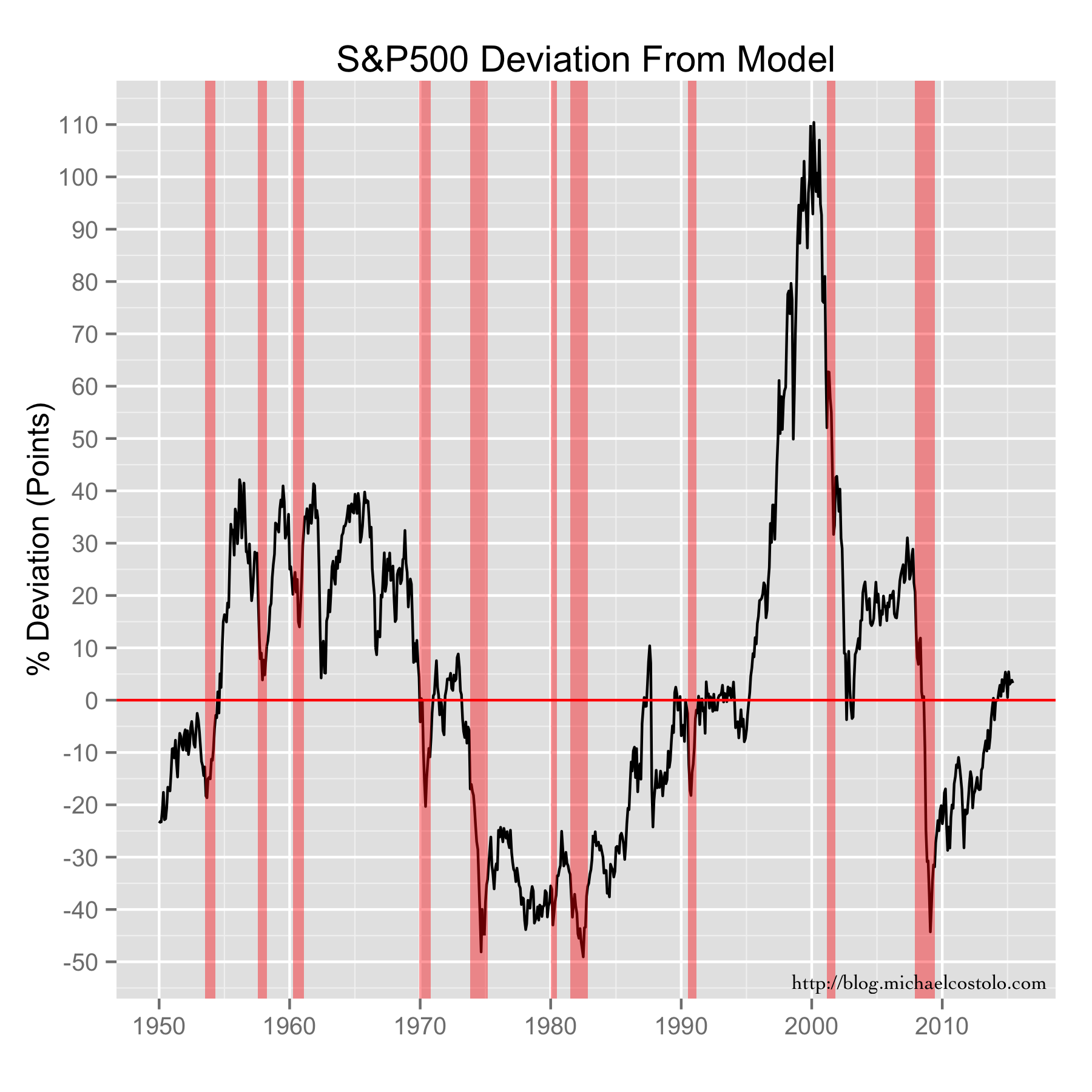




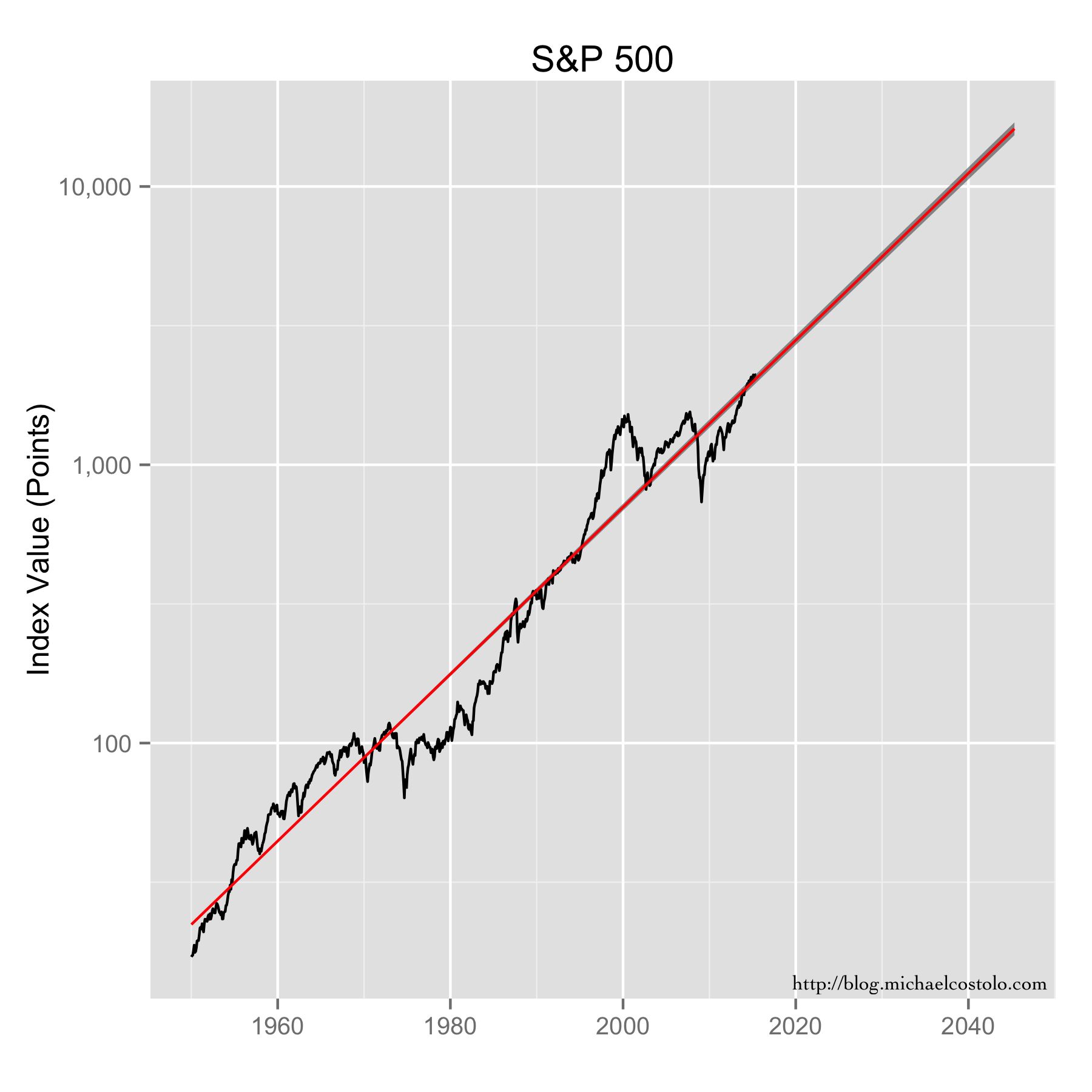
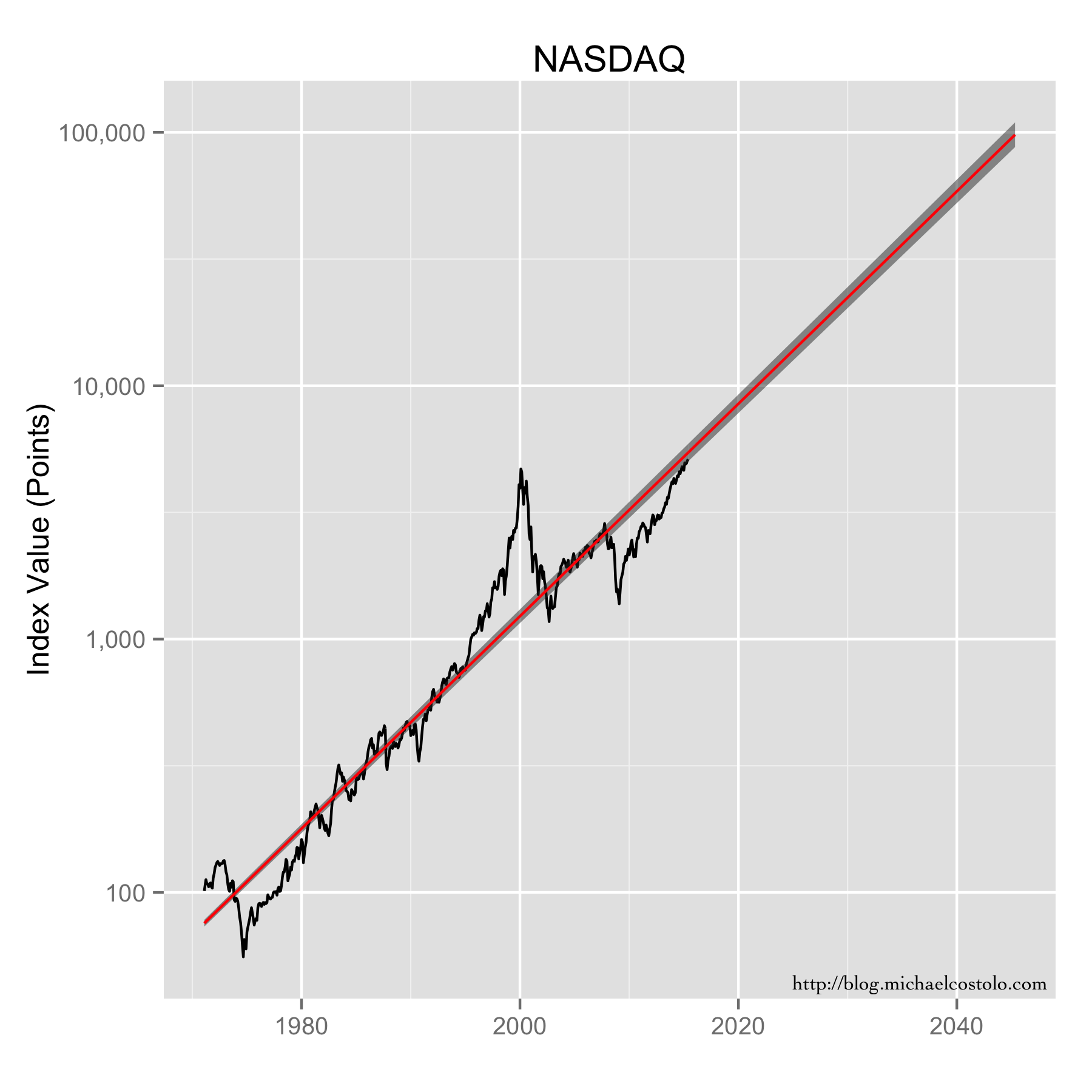




















{kind=link}
{kind=link}